
Share with your network!
During the course of a recent analysis of DNS traffic at a customer site, I noticed a high volume of requests had been made for a relatively small set of domains. As it turned out, the traffic was part of an attack on the customer's DNS infrastructure; however, the point of these requests was initially unclear. Once I eliminated all the requests for well-known, legitimate domains, a pattern emerged in what remained: all requests were for fully qualified domain names (FQDN) having a distinct pattern involving a randomized sub-domain. The pattern was:
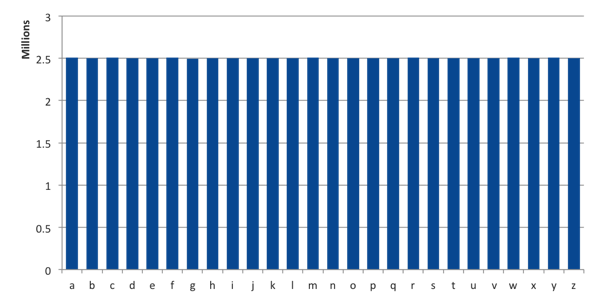
Fig 1. Distribution of characters used in attack sub-domains.[/caption]
Upon digging further, some interesting patterns emerged. First, the number of characters used in the sub-domains fell into very specific buckets as shown here:
[caption id="attachment_5833" align="aligncenter" width="600"]
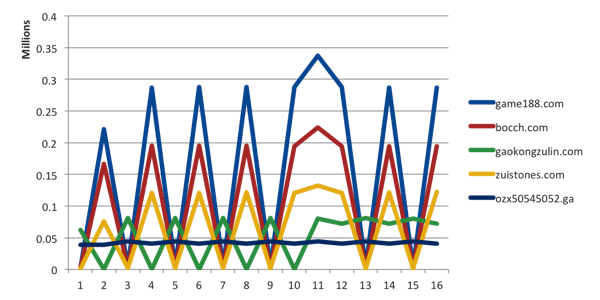
Fig 2. Subdomain lengths for several domains used in the attack.[/caption]
Further, the distribution of characters used in each position within sub-domain strings was strange. Each alternating character position contained only every other character in the alphabet. For example, the first character in a sub-domain would be one of a, c, e, g, i, etc., while the second character would be one of b, d, f, h, j, the third character a, c, e, and so on.
[caption id="attachment_5842" align="aligncenter" width="600"]
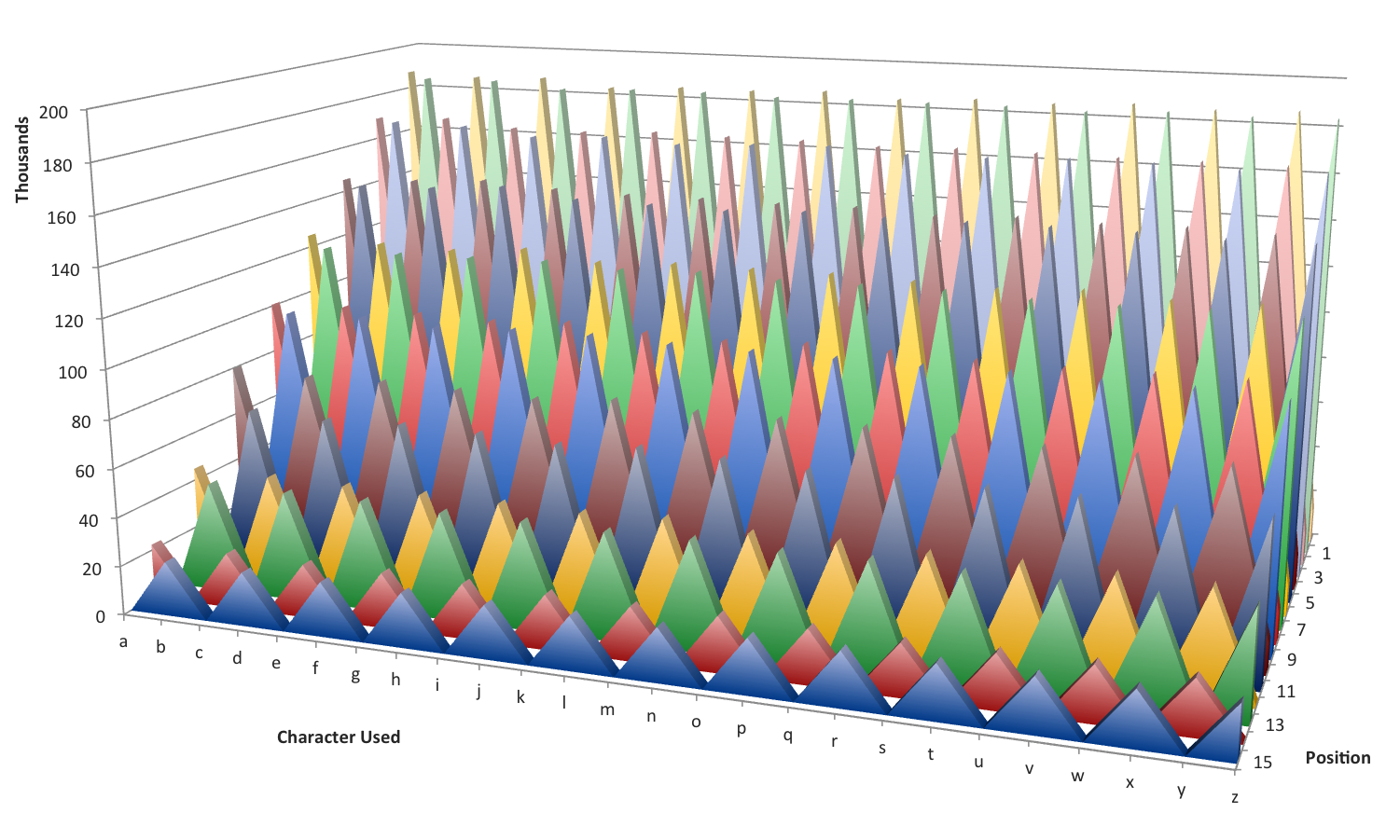
Fig 3. Distribution of game188.com sub-domain characters in each position.[/caption]
If we focus on just a single requesting IP address, the pattern becomes even more clear:
[caption id="attachment_5837" align="aligncenter" width="600"]
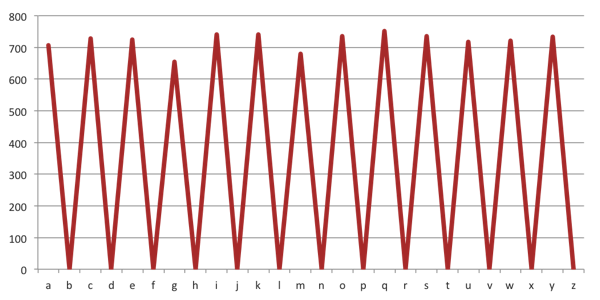
Fig 4. Characters used in game188.com sub-domains requested from a single IP address.[/caption]
This every-other-character scheme further limits the data-carrying capacity of such a sub-domain to base 13, meaning that a minimum of three characters are required to carry a single byte of data. Given that many of the sub-domains I saw were only one character in length with uniform character distribution, it proved impractical for these requests to be transmitting meaningful data. What these patterns do show us; however, is that the requests were sent by the same malware running on the same active botnet.
So what, was the point of these randomized sub-domains, if not for transmitting information? A separate investigation at Cloudmark revealed that malware-infected computers were attacking the customer's own authoritative name servers. When we compared notes, we noticed that the domains used in this attack were the very same ones.
Under normal operation a name server will store the results of previous domain queries in its local cache. This prevents the name server from having to look the same domain up more than once within a given period of time - a feature that increases performance significantly. In the case of this attack, since each request had a unique sub-domain, the name server had to do a lookup for every request it received (and then cache each result). When a name server has to do every single lookup, its performance starts to degrade. Eventually, when the load is great enough, the name server becomes sluggish or unresponsive and this leads to loss of Internet service for the customer.
To put in this context, it became clear that the randomized sub-domains I was seeing served one purpose− to side-step caching of DNS responses, thereby ensuring that all requests hit the authoritative name servers.
[random sub-domain string] . [generic sub-domain (usually "www")] . [sld] . [tld]
For example:
epolanungbmzyzsp.www.game188.com
Initially, my assumption was that these requests came from computers infected with DNS tunneling malware, and that data were being exfiltrated from the customer network via the sub-domain portion of these FQDN's. However, upon closer inspection, this turned out to not be the case...
To begin with, only characters in the range a-z were used in the sub-domains. Since URL encoding is case-insensitive, the character range was limited to base 26, meaning at least two characters would be required to encode one byte of data. This made it a somewhat inefficient medium for information, especially given that standard DNS allows for a range of 38 possible characters: a-z (case insensitive), 0-9, - (hyphen) and . (period)
An analysis of the characters used in the sub-domains showed a flat frequency distribution - no one character was used more than any other. Again, not what you would expect to see if information was being transmitted. The distribution of characters used was so uniform that, of the several million uses per character, the difference between characters was less than half of a single percent.
[caption id="attachment_5829" align="aligncenter" width="600"]